
-
0. 배경
-
1. 좋아요 순으로 정렬하여 No-Offset 방식을 적용한 쿼리
-
1.1 쿼리
-
1.2 문제점 (1) - 여러명이 동시에 요청을 하면, OOM (OutOfMemory) 발생으로 서버가 종료됩니다.
-
1.3 문제점 (2) - No Offset 방식은 정렬 기준이 되는 고유한 키를 가져야 합니다.
-
1.4 문제점 (3) - 게시글을 불러오는데 시간이 너무 오래 걸리거나 장애가 발생합니다.
-
2. 고민 과정
-
2.1 .size()를 없애고 좋아요 개수 쿼리를 따로 하나 빼서 적용한다.
-
2.2 DTO Projection을 전체 활용한다.
-
3. 해결 과정
-
3.1 PostListResponse 분석
-
3.2 좋아요 여부, 좋아요 개수 쿼리 분리 후 합치기
-
3.3 스레드 30개로 테스트 한 결과 -> 커넥션 풀 타임아웃 발생
-
3.4 게시글 개수만큼 발생하던 쿼리를 in 쿼리를 사용하여 한 번에 조회하는 방식으로 변경
-
4. Explain Analyze를 통한 쿼리 분석
-
4.1 반정규화 - Post Entity에 LikeCount 컬럼 추가
-
4.2 Join, Group by, COUNT(), 대용량 데이터 정렬 연산 빠진 쿼리로 개선
-
4.3 2.5s -> 512ms로 조회 성능 개선
-
4.4 수정한 쿼리 Explain Analyze, 아직도 Sort 연산 발생
-
5. 인덱스 생성
-
5.1 LikeCount 인덱스 생성 후 Sort 연산 생략
-
5.2 인덱스 활용으로 512ms -> 123ms로 성능 개선
-
6. 결론
0. 배경
https://byungil.tistory.com/331
게시글 불러오는 쿼리와 마찬가지로, 게시글을 좋아요가 높은 순으로 정렬하여 불러올 때 속도가 매우 느렸고, OutOfMemory 장애가 발생하였습니다.
위 게시글과 마찬가지로 현재 어떠한 상황인지, 어떻게 해결하였는지 정리하였습니다.
1. 좋아요 순으로 정렬하여 No-Offset 방식을 적용한 쿼리
처음 좋아요 순으로 정렬하여 No-Offset 방식을 활용하여 쿼리를 짰습니다.
이 쿼리부터 문제가 있었고 하나하나 문제점을 찾고 해결하겠습니다.
1.1 쿼리

1.2 문제점 (1) - 여러명이 동시에 요청을 하면, OOM (OutOfMemory) 발생으로 서버가 종료됩니다.
한 명이 요청하였을 때 문제가 발생하지 않았지만, 5명이 동시에 요청한다고 가정하고 테스트를 진행했습니다.
OOM으로 서버가 종료됨을 알 수 있습니다.
서버는 ec2 프리티어로 용량이 매우 작은 상태인데, .size()때문에 너무 많은 데이터를 DB에서 동시에 조회하기 때문에 발생합니다.
Jmeter
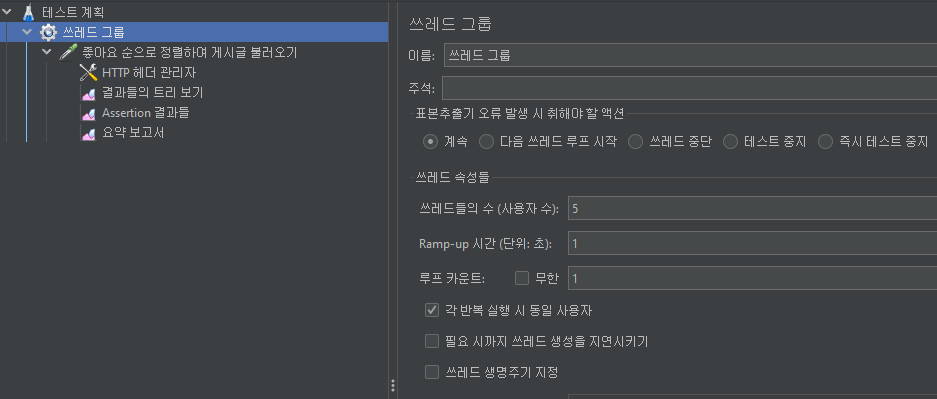
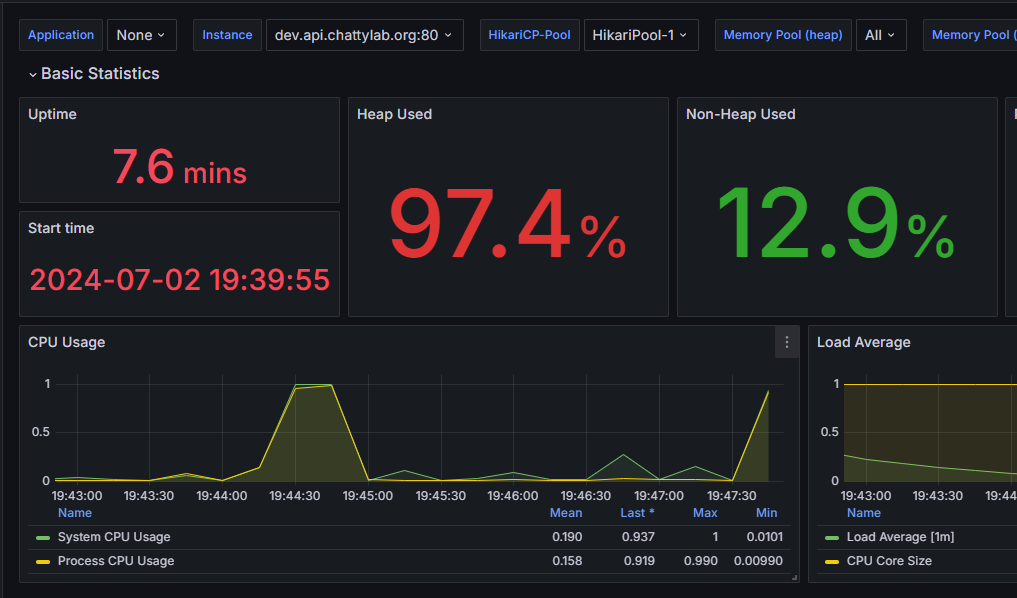
그라파나로 확인하는 CPU Usage, Heap Used
배포 서버 로그

Jmeter 결과
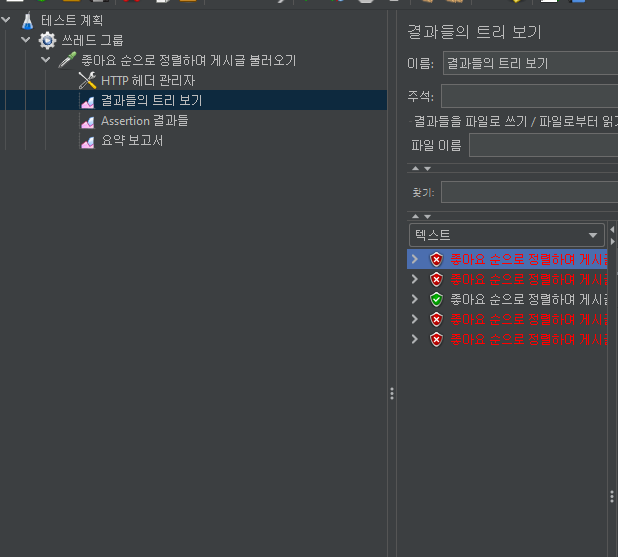
결국 서버 다운
1.3 문제점 (2) - No Offset 방식은 정렬 기준이 되는 고유한 키를 가져야 합니다.
기존 게시글을 불러올 때, WHERE 절을 이용하여 No-Offset 방식을 활용하였습니다.
WHERE 절에 PK 값인 postId를 활용하였지만, 지금 이 쿼리에서는 where절에 PK 값을 활용할 수 없습니다.
좋아요 개수를 Join을 통하여 얻고 있고, 그러한 값은 고유한 값으로 WHERE절에 정의할 수 없었습니다.
이런 쿼리는 똑같은 게시글을 계속 불러오는 현상이 발생하였습니다.
having절에 게시글 좋아요 마지막 값을 이용하려고 했던 제가 바보였습니다..
다음 게시글에 대한 정의를 정확하게 할 수 없기 때문입니다.
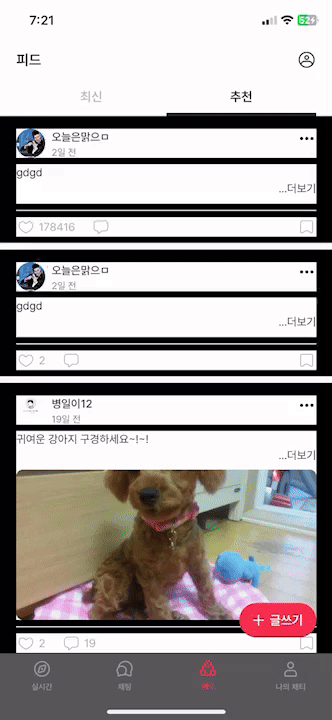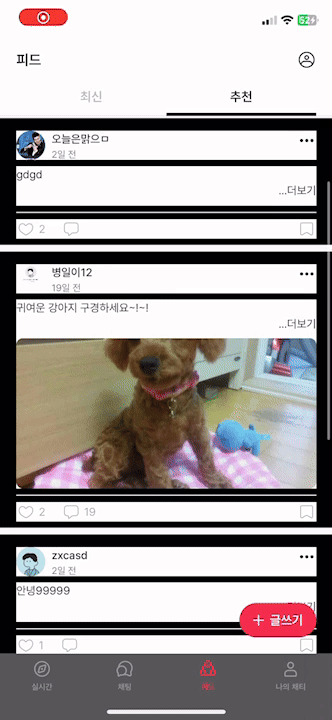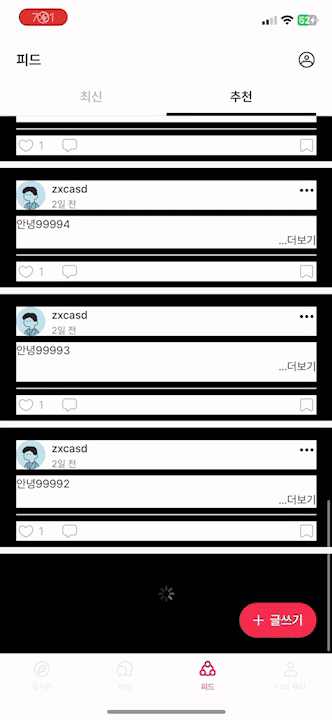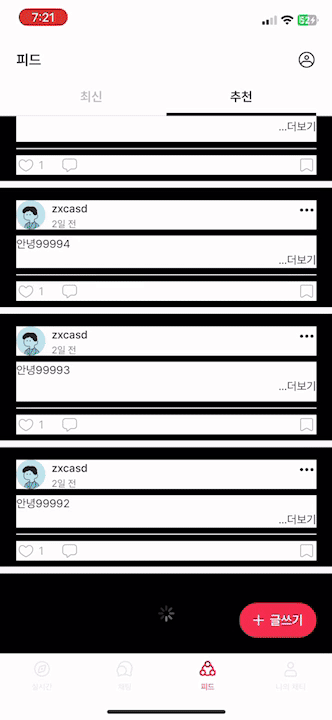
1.4 문제점 (3) - 게시글을 불러오는데 시간이 너무 오래 걸리거나 장애가 발생합니다.
같은 값을 계속 불러오고, 좋아요 개수가 많을 수록 게시글을 불러올 때, 시간이 오래 걸림을 확인할 수 있습니다.
맨 위에 제가 이전에 작성했던 글과 마찬가지로, getPostLikes().size()를 이용하여 개수를 조회했기 때문입니다.
Query에서 사용했던 COUNT(pl.post_like_id)를 전혀 활용하지 못하고, PostResponse.of에서 마찬가지로 .size()로 모든 게시글을 DB에서 불러와 list에 담고 그 사이즈를 출력했기 때문에 발생한 문제입니다.
좋아요 개수로 정렬하여 Post를 불러왔지만, 개수는 사용하지 못하는 상황이고 그 개수는 다시 DB를 조회하여 list에 담는 치명적인 실수입니다.
로컬 기준 - 5s
현재 서버 기준 좋아요 순으로 정렬하여 값을 불러오는 데 6s가 걸립니다.
좋아요가 많으면 마찬가지로 OutOfMemory 에러가 발생합니다.
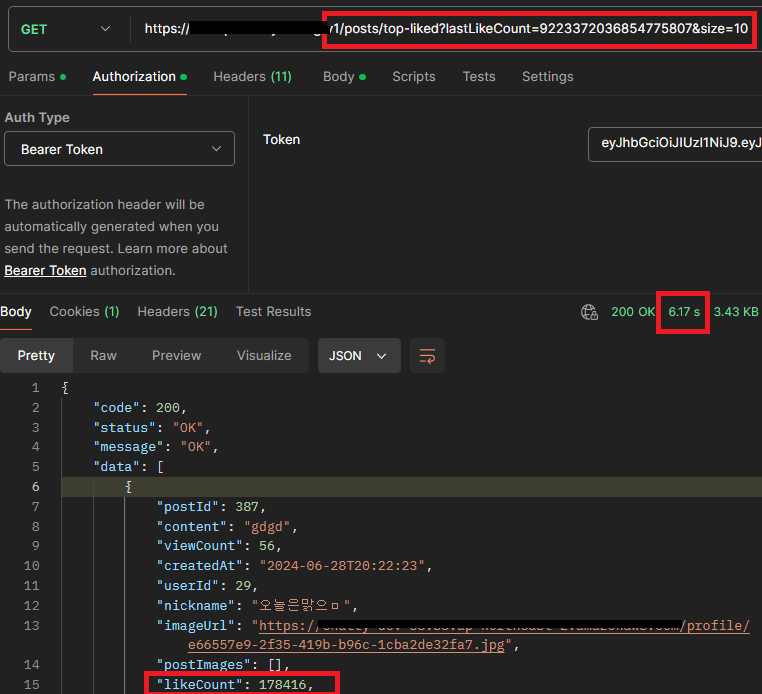
어떻게 개선하는지 알아보겠습니다.
2. 고민 과정
2.1 .size()를 없애고 좋아요 개수 쿼리를 따로 하나 빼서 적용한다.
기존 단건 조회에서는 count 쿼리를 하나 만들어서 .size()대신, 개수를 직접 넣어줬습니다.
하지만 이런 방법은 List를 조회할 때 적용할 수 없었습니다.
이 로직에서 PostListResponse 값에 count한 값을 넣어줄 수 없기 때문입니다.
따라서 이 방법은 불가능합니다.
2.2 DTO Projection을 전체 활용한다.
PostListResponse에는 컬럼이 13개가 존재합니다.
DTO Projection을 활용하기에는 컬럼이 너무 많고 오히려 가독성을 안 좋게 만든다고 판단하였습니다.
DTO Projection은 적용하지 않았습니다.
3. 해결 과정
3.1 PostListResponse 분석
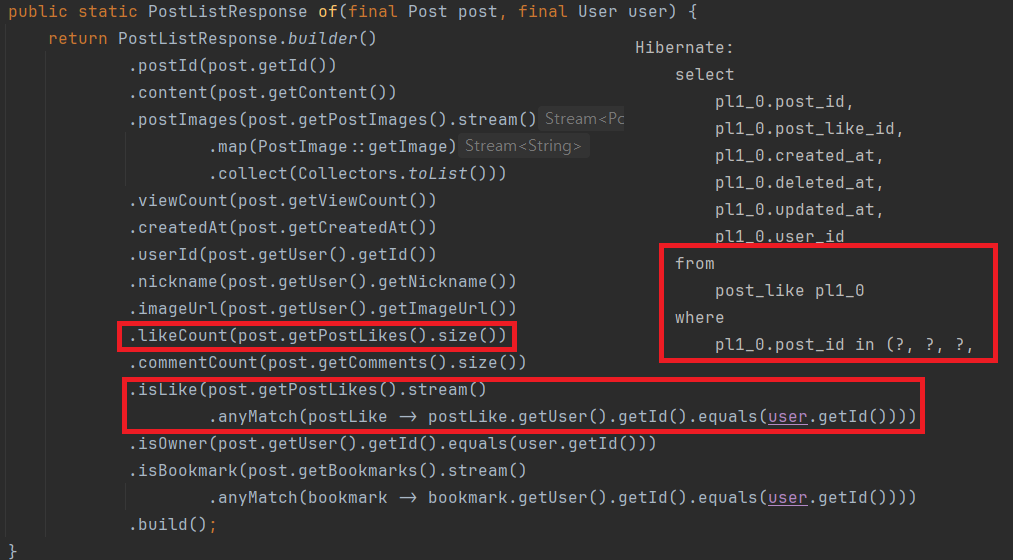
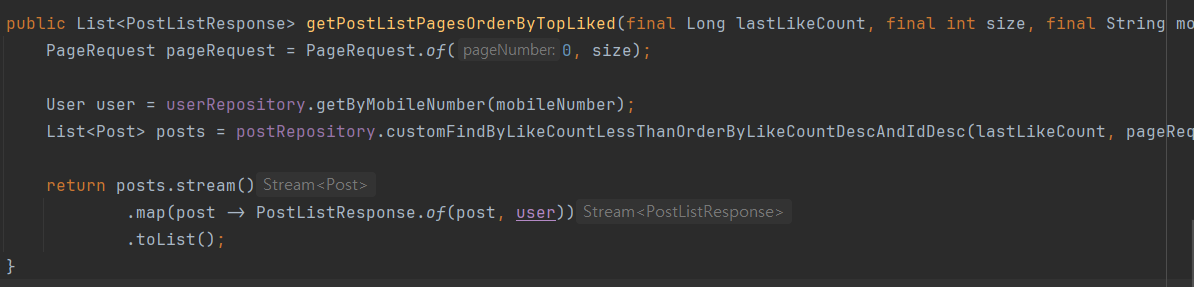
getPostLikes()를 이용하여 likeCount, isLike값을 불러왔기 때문에 불필요한 쿼리가 발생하였습니다.
데이터가 적을 때는 문제가 없지만, 데이터가 많으면 성능, 서비스 장에 등 여러가지 문제가 발생합니다.
일단, likeCount와 isLike를 먼저 개선하는 과정입니다.
3.2 좋아요 여부, 좋아요 개수 쿼리 분리 후 합치기
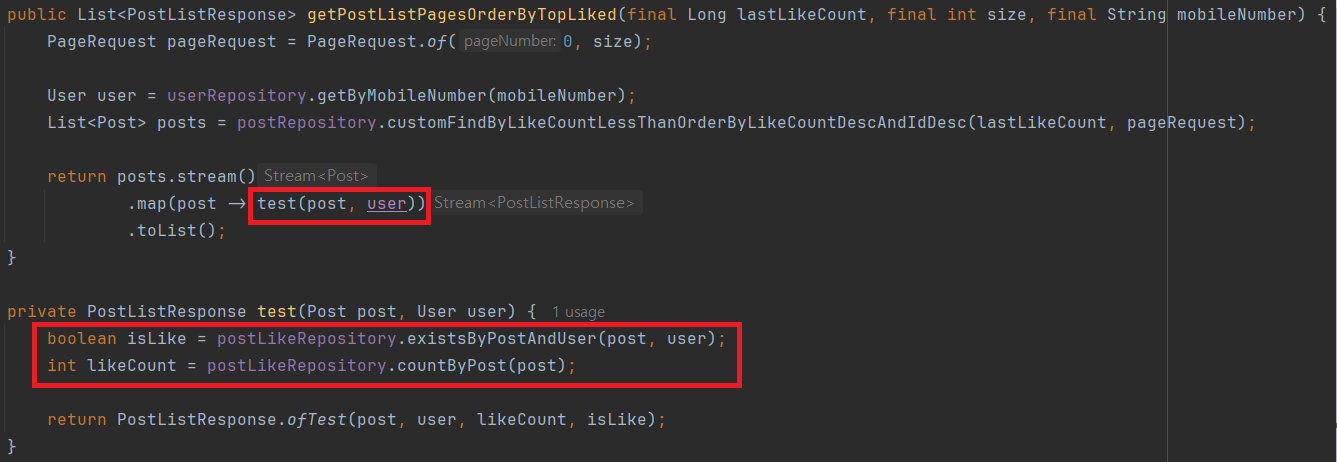
쿼리를 분리하였습니다.
이제 게시글을 불러올 때, 그 게시글에 대한 좋아요 개수와 여부는 따로 쿼리가 날라가는 형식입니다.
이렇게 로직을 구성하였을 때, 성능은 기존보다 훨씬 좋아졌음을 알 수 있습니다. 성능 50% 향상
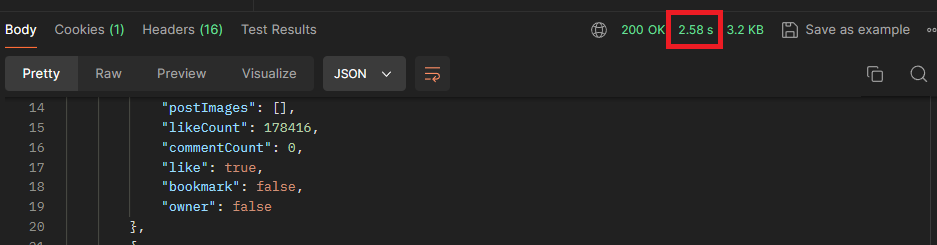
배포 서버
성능 약 58% 향상
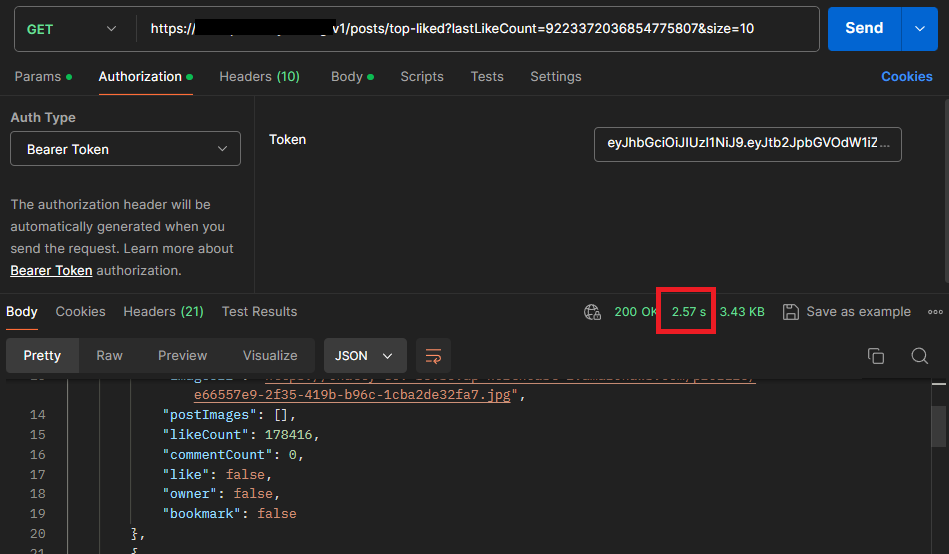
하지만 여전히 느린 속도를 기록하였고, 게시글을 불러오는 개수만큼 count쿼리와 exists 쿼리가 발생하였습니다.
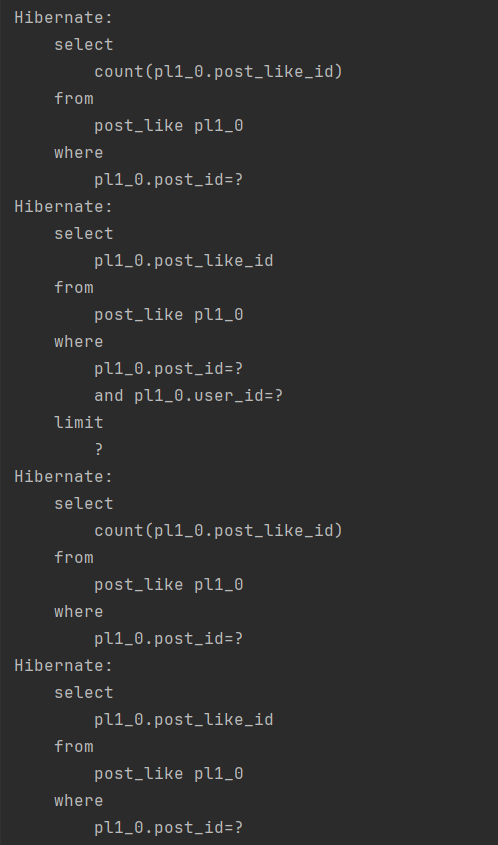
Jmeter 쓰레드5 테스트
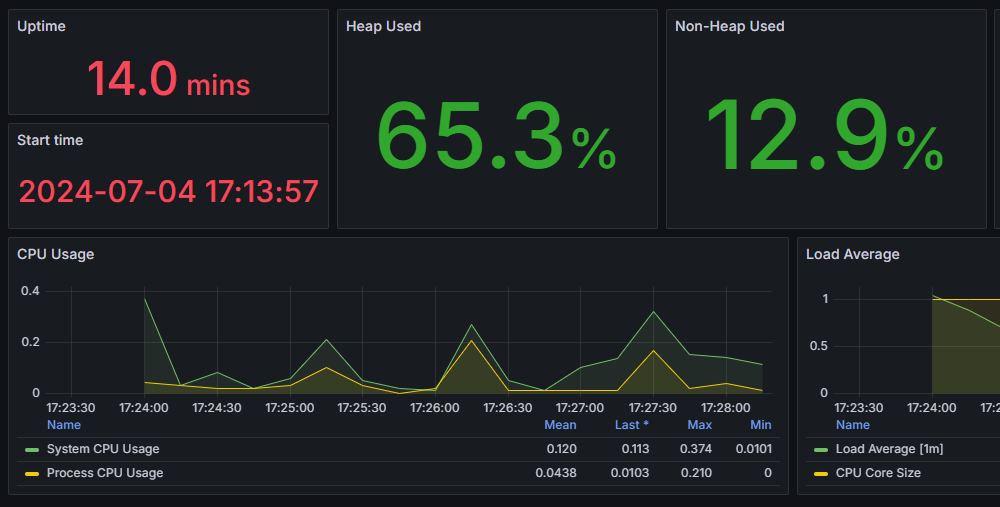
확실히 Heap Used와 CPU Usage가 안정적임을 확인할 수 있습니다.
3.3 스레드 30개로 테스트 한 결과 -> 커넥션 풀 타임아웃 발생

쿼리를 처리하는 속도는 2.5초 이상이 소모됩니다.
커넥션 풀은 최대 10개로 셋팅되어있고, 10개가 사용중일 때, 나머지 20개는 대기 상태이며 대기 상태가 30초가 넘었을 때 타임아웃이 발생합니다.
커넥션 풀 사이즈를 늘려서 해결하는 것보다 쿼리 속도를 줄여서 해결하는 방식이 현재 상황에 더 적합하다고 판단하였기 때문에 추가적으로 개선해보겠습니다.
3.4 게시글 개수만큼 발생하던 쿼리를 in 쿼리를 사용하여 한 번에 조회하는 방식으로 변경
현재 쿼리는 불러오는 게시글 하나당 - 게시글 좋아요 개수 조회 쿼리, 게시글 좋아요 여부 쿼리가 발생합니다.
게시글 목록을 10개 불러온다고 가정하면, 게시글 목록 조회 10개 + 좋아요 개수 10 + 좋아요 여부 10
총 30번 SELECT문이 실행되고, 지금 당장 문제는 없지만 네트워크 오버헤드가 각 쿼리마다 발생합니다.
데이터베이스 연결을 여러 번 연결하게 되고, 도중에 문제가 생기면 장애로 이어지기 때문에 in 쿼리와 DTO Projection을 활용하여 횟수를 줄이는 방법을 적용하였습니다.
HashMap을 이용하여 좋아요 여부를 저장하였습니다.
List<Long> postIds = posts.stream()
.map(Post::getId)
.toList();
List<PostLike> byUserAndPostIds = postLikeRepository.findByUserAndPostIds(user, postIds);
Map<Long, Boolean> likeMap = new HashMap<>();
for (PostLike like : byUserAndPostIds) {
likeMap.put(like.getPost().getId(), true);
}
for (Long postId : postIds) {
likeMap.putIfAbsent(postId, false);
}HashMap을 이용하여 좋아요 개수를 저장하였습니다.
List<PostLikeCountResponse> likeCount = postLikeRepository.findByPostIdsAndLikeCount(postIds);
Map<Long, Long> likeCountMap = new HashMap<>();
for (PostLikeCountResponse postLikeCountResponse : likeCount) {
likeCountMap.put(postLikeCountResponse.getPostId(), postLikeCountResponse.getLikeCount());
}
in 쿼리를 사용한다고 해서 조회 속도가 빨라지는 것은 아닙니다.
근본적인 해결을 위해 현재 게시글 목록을 불러오는 쿼리를 분석하여 어떤 부분에서 시간이 오래걸리는지 확인해봤습니다.
4. Explain Analyze를 통한 쿼리 분석
explain analyze
select p.*, COUNT(pl.post_like_id) as LikeCount
from post p inner join post_like pl
on p.post_id = pl.post_id
group by p.post_id
having LikeCount < 1000000
order by LikeCount Desc, p.post_id Desc
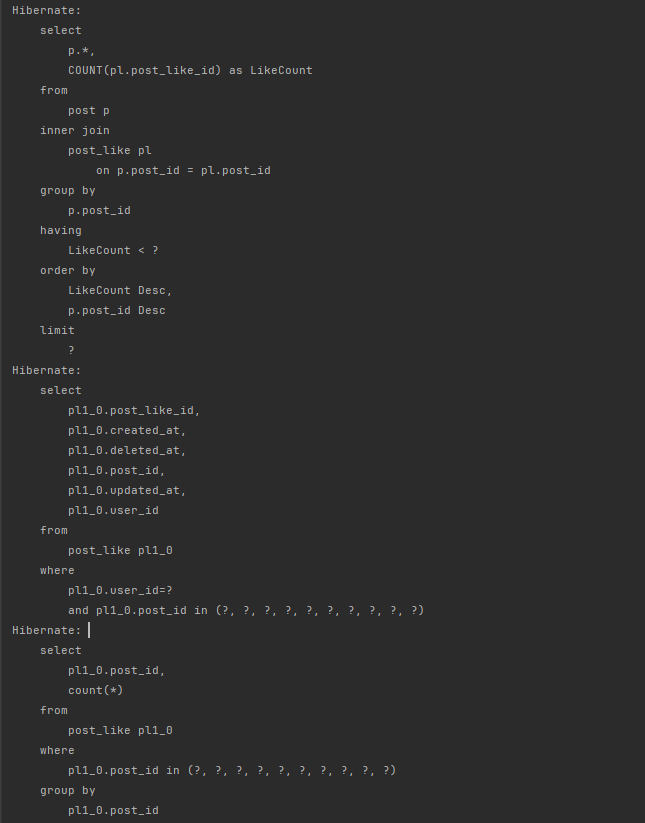
limit 10;현재 쿼리는 Post와 PostLike를 조인하고, postId를 그룹화한 후, 정렬을 합니다.
explain analyze를 통하여 어떻게 쿼리가 실행되고 있는지 확인해봤습니다.

현재 Post에는 45만개의 데이터가 존재합니다.
45만개의 데이터를 정렬하는 과정에서 시간이 오래 걸림을 확인할 수 있습니다.
그럼 정렬하는 과정이 없으면 좋아요가 많은 순으로 데이터를 불러올 수 없는 상황입니다.
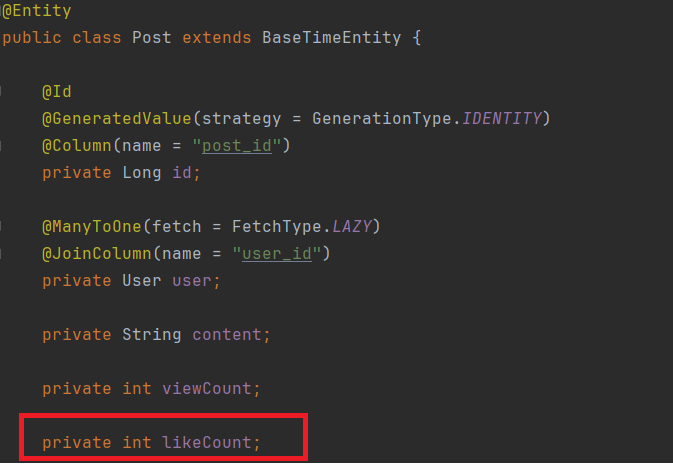
그래서 저는 반정규화를 통해 LikeCount를 Post 엔티티에 컬럼으로 추가하였습니다.
4.1 반정규화 - Post Entity에 LikeCount 컬럼 추가
alter table post add like_count INT;
update post set like_count = (
select count(*)
from post_like
where post_like.post_id = post.post_id
);
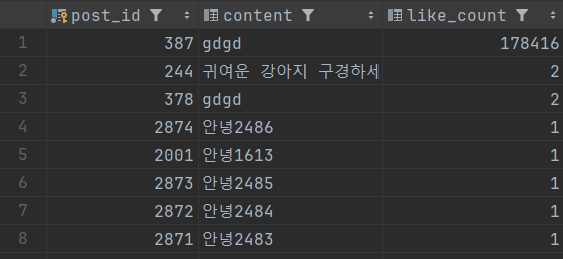
데이터가 잘 들어간 것을 확인할 수 있습니다.
4.2 Join, Group by, COUNT(), 대용량 데이터 정렬 연산 빠진 쿼리로 개선
기존 쿼리에는 Join, Group by, COUNT(), 대용량 데이터 정렬이 존재했습니다.
그런데 현재 반정규화를 통하여 좋아요 개수 컬럼이 존재하기 때문에 위에 나와있는 연산이 다 빠질 수 있게 되었습니다.

4.3 2.5s -> 512ms로 조회 성능 개선
2.5초에서 512ms로 조회 성능을 개선하였습니다.
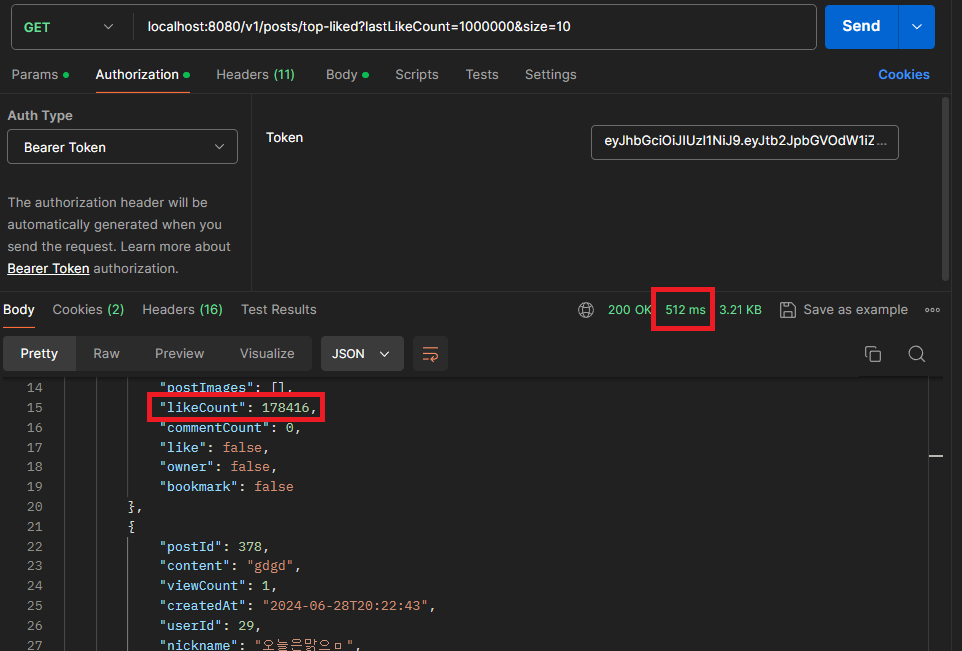
추가적으로 엔티티에 컬럼을 추가하였기 때문에, 기존에 사용하던 in쿼리를 활용하여 postId 값으로 좋아요 개수 COUNT 쿼리를 날릴 필요가 없습니다.
4.4 수정한 쿼리 Explain Analyze, 아직도 Sort 연산 발생
explain analyze
select *
from post
order by like_count desc, post_id desc
limit 10;현재 쿼리는 Using temporary와 Using filesort가 발생했던 쿼리를 개선하여 성능을 향상시켰습니다.
현재 쿼리를 다시 explain 하였더니 여전히 Using filesort가 발생하였고, 45만개 데이터를 Sort하고 있었습니다.

성능을 더 개선하기 위해서 Sort연산이 발생하면 안 되기 때문에, 인덱스를 적절하게 설정하여 Sort 연산을 생략하겠습니다.
5. 인덱스 생성
5.1 LikeCount 인덱스 생성 후 Sort 연산 생략

Limit 연산이 존재하기 때문에, 인덱스를 이용하면 정렬된 순서로 데이터를 빠르게 검색할 수 있으므로 정렬 연산을 줄일 수 있습니다.

5.2 인덱스 활용으로 512ms -> 123ms로 성능 개선
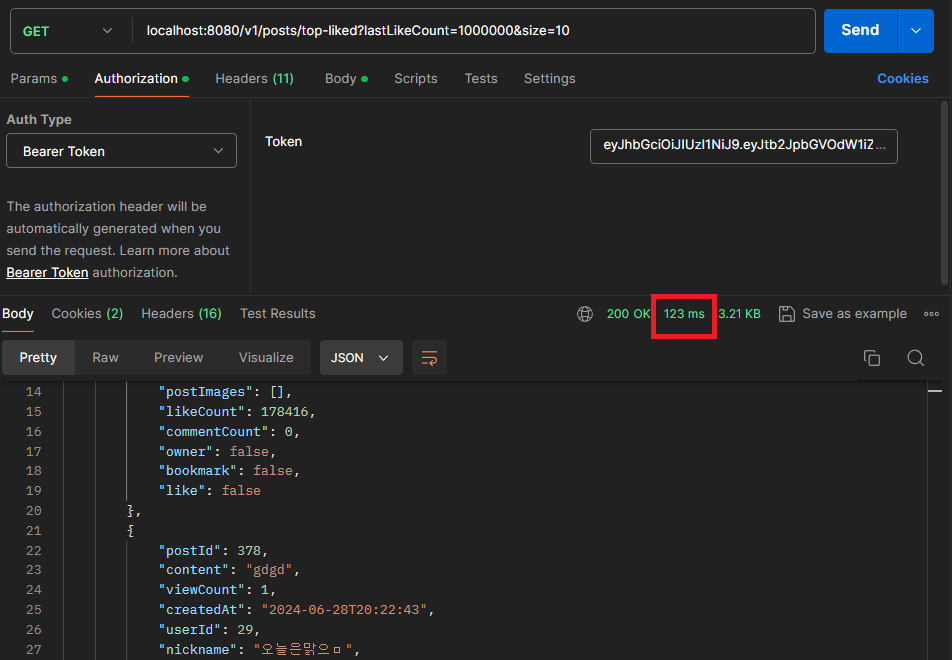
인덱스를 활용하여 정렬된 순서로 데이터를 빠르게 검색할 수 있습니다.
인덱스로 인하여 데이터 전체 검색 후 정렬 -> 정렬되어있는 데이터 사용으로 바뀌었기 때문에 조회 속도가 더 빨라질 수 있습니다.
6. 결론
좋아요 개수를 이용하여 정렬을 해야 하기 때문에 Join을 통한 연산은 비용이 너무 많이 드는 것을 알 수 있었고, 반정규화를 통하여 개선할 수 있었습니다.
LikeCount를 컬럼으로 뺀다는 것이 항상 장점만 존재하는 것은 아닙니다. 데이터 정합성 문제가 발생할 수 있고, 작성한 코드에 따라 데드락도 발생할 수 있습니다.
현재 상황에 맞게 해결하는 방법을 찾는게 중요합니다.
저는 반정규화를 통하여 성능을 개선하였습니다.
처음에 작성한 쿼리는 5s,
좋아요 여부와 개수 쿼리 분리 후 2.5s,
좋아요 개수와 여부 조회 in을 활용하여 네트워크 오버헤드를 줄임,
Post Entity에 LikeCount 컬럼을 추가하여 512ms,
인덱스 생성으로 Sort연산을 생략하여 123ms 까지 성능을 개선하였습니다.
결과적으로 5s -> 123ms 성능 약 97% 향상되었습니다.
0. 배경
https://byungil.tistory.com/331
게시글 불러오는 쿼리와 마찬가지로, 게시글을 좋아요가 높은 순으로 정렬하여 불러올 때 속도가 매우 느렸고, OutOfMemory 장애가 발생하였습니다.
위 게시글과 마찬가지로 현재 어떠한 상황인지, 어떻게 해결하였는지 정리하였습니다.
1. 좋아요 순으로 정렬하여 No-Offset 방식을 적용한 쿼리
처음 좋아요 순으로 정렬하여 No-Offset 방식을 활용하여 쿼리를 짰습니다.
이 쿼리부터 문제가 있었고 하나하나 문제점을 찾고 해결하겠습니다.
1.1 쿼리
1.2 문제점 (1) - 여러명이 동시에 요청을 하면, OOM (OutOfMemory) 발생으로 서버가 종료됩니다.
한 명이 요청하였을 때 문제가 발생하지 않았지만, 5명이 동시에 요청한다고 가정하고 테스트를 진행했습니다.
OOM으로 서버가 종료됨을 알 수 있습니다.
서버는 ec2 프리티어로 용량이 매우 작은 상태인데, .size()때문에 너무 많은 데이터를 DB에서 동시에 조회하기 때문에 발생합니다.
Jmeter
그라파나로 확인하는 CPU Usage, Heap Used
배포 서버 로그
Jmeter 결과
결국 서버 다운
1.3 문제점 (2) - No Offset 방식은 정렬 기준이 되는 고유한 키를 가져야 합니다.
기존 게시글을 불러올 때, WHERE 절을 이용하여 No-Offset 방식을 활용하였습니다.
WHERE 절에 PK 값인 postId를 활용하였지만, 지금 이 쿼리에서는 where절에 PK 값을 활용할 수 없습니다.
좋아요 개수를 Join을 통하여 얻고 있고, 그러한 값은 고유한 값으로 WHERE절에 정의할 수 없었습니다.
이런 쿼리는 똑같은 게시글을 계속 불러오는 현상이 발생하였습니다.
having절에 게시글 좋아요 마지막 값을 이용하려고 했던 제가 바보였습니다..
다음 게시글에 대한 정의를 정확하게 할 수 없기 때문입니다.
1.4 문제점 (3) - 게시글을 불러오는데 시간이 너무 오래 걸리거나 장애가 발생합니다.
같은 값을 계속 불러오고, 좋아요 개수가 많을 수록 게시글을 불러올 때, 시간이 오래 걸림을 확인할 수 있습니다.
맨 위에 제가 이전에 작성했던 글과 마찬가지로, getPostLikes().size()를 이용하여 개수를 조회했기 때문입니다.
Query에서 사용했던 COUNT(pl.post_like_id)를 전혀 활용하지 못하고, PostResponse.of에서 마찬가지로 .size()로 모든 게시글을 DB에서 불러와 list에 담고 그 사이즈를 출력했기 때문에 발생한 문제입니다.
좋아요 개수로 정렬하여 Post를 불러왔지만, 개수는 사용하지 못하는 상황이고 그 개수는 다시 DB를 조회하여 list에 담는 치명적인 실수입니다.
로컬 기준 - 5s
현재 서버 기준 좋아요 순으로 정렬하여 값을 불러오는 데 6s가 걸립니다.
좋아요가 많으면 마찬가지로 OutOfMemory 에러가 발생합니다.
어떻게 개선하는지 알아보겠습니다.
2. 고민 과정
2.1 .size()를 없애고 좋아요 개수 쿼리를 따로 하나 빼서 적용한다.
기존 단건 조회에서는 count 쿼리를 하나 만들어서 .size()대신, 개수를 직접 넣어줬습니다.
하지만 이런 방법은 List를 조회할 때 적용할 수 없었습니다.
이 로직에서 PostListResponse 값에 count한 값을 넣어줄 수 없기 때문입니다.
따라서 이 방법은 불가능합니다.
2.2 DTO Projection을 전체 활용한다.
PostListResponse에는 컬럼이 13개가 존재합니다.
DTO Projection을 활용하기에는 컬럼이 너무 많고 오히려 가독성을 안 좋게 만든다고 판단하였습니다.
DTO Projection은 적용하지 않았습니다.
3. 해결 과정
3.1 PostListResponse 분석
getPostLikes()를 이용하여 likeCount, isLike값을 불러왔기 때문에 불필요한 쿼리가 발생하였습니다.
데이터가 적을 때는 문제가 없지만, 데이터가 많으면 성능, 서비스 장에 등 여러가지 문제가 발생합니다.
일단, likeCount와 isLike를 먼저 개선하는 과정입니다.
3.2 좋아요 여부, 좋아요 개수 쿼리 분리 후 합치기
쿼리를 분리하였습니다.
이제 게시글을 불러올 때, 그 게시글에 대한 좋아요 개수와 여부는 따로 쿼리가 날라가는 형식입니다.
이렇게 로직을 구성하였을 때, 성능은 기존보다 훨씬 좋아졌음을 알 수 있습니다. 성능 50% 향상
배포 서버
성능 약 58% 향상
하지만 여전히 느린 속도를 기록하였고, 게시글을 불러오는 개수만큼 count쿼리와 exists 쿼리가 발생하였습니다.
Jmeter 쓰레드5 테스트
확실히 Heap Used와 CPU Usage가 안정적임을 확인할 수 있습니다.
3.3 스레드 30개로 테스트 한 결과 -> 커넥션 풀 타임아웃 발생
쿼리를 처리하는 속도는 2.5초 이상이 소모됩니다.
커넥션 풀은 최대 10개로 셋팅되어있고, 10개가 사용중일 때, 나머지 20개는 대기 상태이며 대기 상태가 30초가 넘었을 때 타임아웃이 발생합니다.
커넥션 풀 사이즈를 늘려서 해결하는 것보다 쿼리 속도를 줄여서 해결하는 방식이 현재 상황에 더 적합하다고 판단하였기 때문에 추가적으로 개선해보겠습니다.
3.4 게시글 개수만큼 발생하던 쿼리를 in 쿼리를 사용하여 한 번에 조회하는 방식으로 변경
현재 쿼리는 불러오는 게시글 하나당 - 게시글 좋아요 개수 조회 쿼리, 게시글 좋아요 여부 쿼리가 발생합니다.
게시글 목록을 10개 불러온다고 가정하면, 게시글 목록 조회 10개 + 좋아요 개수 10 + 좋아요 여부 10
총 30번 SELECT문이 실행되고, 지금 당장 문제는 없지만 네트워크 오버헤드가 각 쿼리마다 발생합니다.
데이터베이스 연결을 여러 번 연결하게 되고, 도중에 문제가 생기면 장애로 이어지기 때문에 in 쿼리와 DTO Projection을 활용하여 횟수를 줄이는 방법을 적용하였습니다.
HashMap을 이용하여 좋아요 여부를 저장하였습니다.
List<Long> postIds = posts.stream()
.map(Post::getId)
.toList();
List<PostLike> byUserAndPostIds = postLikeRepository.findByUserAndPostIds(user, postIds);
Map<Long, Boolean> likeMap = new HashMap<>();
for (PostLike like : byUserAndPostIds) {
likeMap.put(like.getPost().getId(), true);
}
for (Long postId : postIds) {
likeMap.putIfAbsent(postId, false);
}HashMap을 이용하여 좋아요 개수를 저장하였습니다.
List<PostLikeCountResponse> likeCount = postLikeRepository.findByPostIdsAndLikeCount(postIds);
Map<Long, Long> likeCountMap = new HashMap<>();
for (PostLikeCountResponse postLikeCountResponse : likeCount) {
likeCountMap.put(postLikeCountResponse.getPostId(), postLikeCountResponse.getLikeCount());
}in 쿼리를 사용한다고 해서 조회 속도가 빨라지는 것은 아닙니다.
근본적인 해결을 위해 현재 게시글 목록을 불러오는 쿼리를 분석하여 어떤 부분에서 시간이 오래걸리는지 확인해봤습니다.
4. Explain Analyze를 통한 쿼리 분석
explain analyze
select p.*, COUNT(pl.post_like_id) as LikeCount
from post p inner join post_like pl
on p.post_id = pl.post_id
group by p.post_id
having LikeCount < 1000000
order by LikeCount Desc, p.post_id Desc
limit 10;현재 쿼리는 Post와 PostLike를 조인하고, postId를 그룹화한 후, 정렬을 합니다.
explain analyze를 통하여 어떻게 쿼리가 실행되고 있는지 확인해봤습니다.
현재 Post에는 45만개의 데이터가 존재합니다.
45만개의 데이터를 정렬하는 과정에서 시간이 오래 걸림을 확인할 수 있습니다.
그럼 정렬하는 과정이 없으면 좋아요가 많은 순으로 데이터를 불러올 수 없는 상황입니다.
그래서 저는 반정규화를 통해 LikeCount를 Post 엔티티에 컬럼으로 추가하였습니다.
4.1 반정규화 - Post Entity에 LikeCount 컬럼 추가
alter table post add like_count INT;
update post set like_count = (
select count(*)
from post_like
where post_like.post_id = post.post_id
);데이터가 잘 들어간 것을 확인할 수 있습니다.
4.2 Join, Group by, COUNT(), 대용량 데이터 정렬 연산 빠진 쿼리로 개선
기존 쿼리에는 Join, Group by, COUNT(), 대용량 데이터 정렬이 존재했습니다.
그런데 현재 반정규화를 통하여 좋아요 개수 컬럼이 존재하기 때문에 위에 나와있는 연산이 다 빠질 수 있게 되었습니다.
4.3 2.5s -> 512ms로 조회 성능 개선
2.5초에서 512ms로 조회 성능을 개선하였습니다.
추가적으로 엔티티에 컬럼을 추가하였기 때문에, 기존에 사용하던 in쿼리를 활용하여 postId 값으로 좋아요 개수 COUNT 쿼리를 날릴 필요가 없습니다.
4.4 수정한 쿼리 Explain Analyze, 아직도 Sort 연산 발생
explain analyze
select *
from post
order by like_count desc, post_id desc
limit 10;현재 쿼리는 Using temporary와 Using filesort가 발생했던 쿼리를 개선하여 성능을 향상시켰습니다.
현재 쿼리를 다시 explain 하였더니 여전히 Using filesort가 발생하였고, 45만개 데이터를 Sort하고 있었습니다.
성능을 더 개선하기 위해서 Sort연산이 발생하면 안 되기 때문에, 인덱스를 적절하게 설정하여 Sort 연산을 생략하겠습니다.
5. 인덱스 생성
5.1 LikeCount 인덱스 생성 후 Sort 연산 생략
Limit 연산이 존재하기 때문에, 인덱스를 이용하면 정렬된 순서로 데이터를 빠르게 검색할 수 있으므로 정렬 연산을 줄일 수 있습니다.
5.2 인덱스 활용으로 512ms -> 123ms로 성능 개선
인덱스를 활용하여 정렬된 순서로 데이터를 빠르게 검색할 수 있습니다.
인덱스로 인하여 데이터 전체 검색 후 정렬 -> 정렬되어있는 데이터 사용으로 바뀌었기 때문에 조회 속도가 더 빨라질 수 있습니다.
6. 결론
좋아요 개수를 이용하여 정렬을 해야 하기 때문에 Join을 통한 연산은 비용이 너무 많이 드는 것을 알 수 있었고, 반정규화를 통하여 개선할 수 있었습니다.
LikeCount를 컬럼으로 뺀다는 것이 항상 장점만 존재하는 것은 아닙니다. 데이터 정합성 문제가 발생할 수 있고, 작성한 코드에 따라 데드락도 발생할 수 있습니다.
현재 상황에 맞게 해결하는 방법을 찾는게 중요합니다.
저는 반정규화를 통하여 성능을 개선하였습니다.
처음에 작성한 쿼리는 5s,
좋아요 여부와 개수 쿼리 분리 후 2.5s,
좋아요 개수와 여부 조회 in을 활용하여 네트워크 오버헤드를 줄임,
Post Entity에 LikeCount 컬럼을 추가하여 512ms,
인덱스 생성으로 Sort연산을 생략하여 123ms 까지 성능을 개선하였습니다.
결과적으로 5s -> 123ms 성능 약 97% 향상되었습니다.