
0. 배경
JPA로 개발하면서 N + 1 문제를 만나 헤맸던 부분과 제대로 처리하지 않으면 성능 저하, 장애로 이어질 수 있다는 부분을 깨닫고 정리하였습니다.
1. JPA: N + 1 문제
정의
N + 1 문제는 ORM 기술에서 특정 객체를 대상으로 수행한 쿼리가 해당 객체가 가지고 있는 연관관계를 조회하게 되면서 N번 추가적인 쿼리가 발생하는 문제입니다.
예시
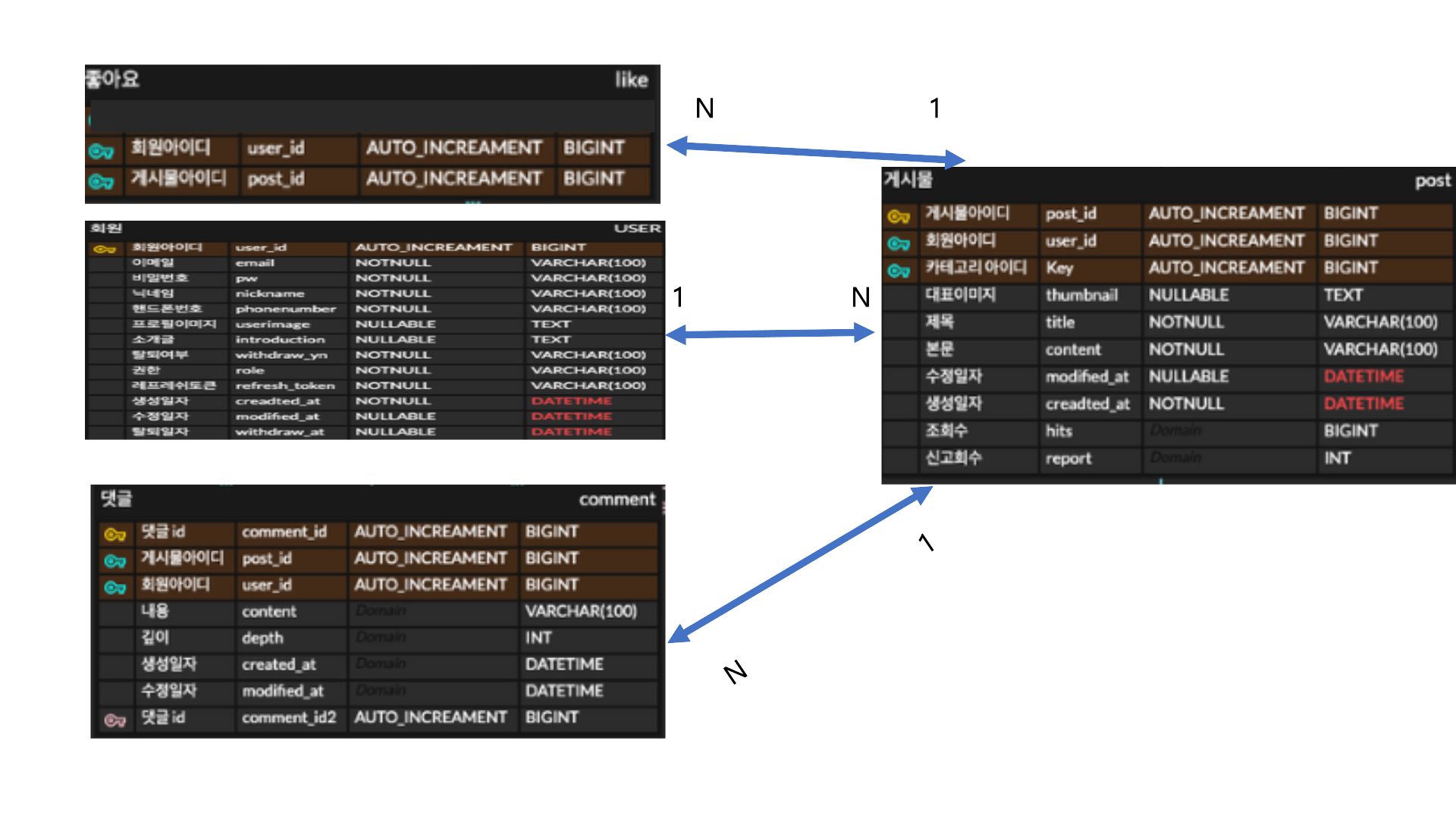
간단하게 구조를 살펴보겠습니다.
1. POST는 LIKE, USER, COMMENT를 갖고 있습니다.
2. PostRepository에서 여러 Post를 조회하는 메소드를 호출하면 1개의 SELECT 쿼리로 POST가 조회 되고,
FetchType.LAZY 설정으로 인해 LIKE, USER, COMMENT는 프록시 객체가 생성됩니다.
3. 해당 컬렉션을 코드내에서 조회하려고 할 때, N개의 SELECT 쿼리가 발생합니다.
N + 1이 문제가 되는 이유
예시 코드
@Query(value = "select p.*, COUNT(pl.post_like_id) as LikeCount " +
"from post p inner join post_like pl " +
"on p.post_id = pl.post_id " +
"where p.post_id < 10000 " +
"group by p.post_id " +
"order by LikeCount Desc, p.post_id Desc", nativeQuery = true)
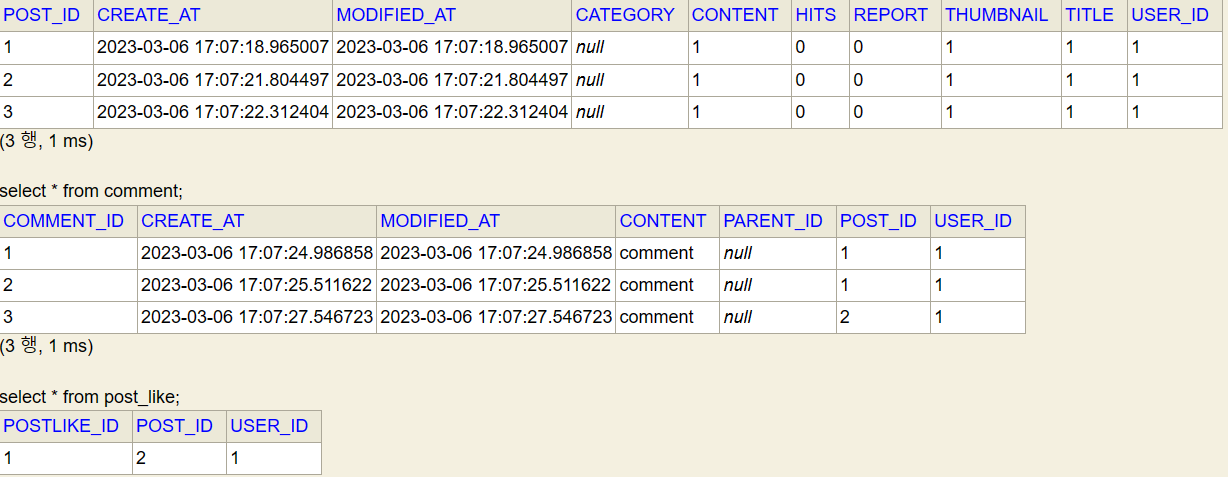
List<Post> customFindAllByLikeCountLessThanOrderByLikeCountDescAndPostIdDesc();게시글 10,000 개를 조회할 때 걸린 속도
게시글 10,000개를 조회할 때 N + 1로 인하여 약 13초 정도 소모되었습니다.
쿼리가 배수적으로 증가하여 DB에 큰 부담이 발생하고 장애 요인이 될 수 있습니다.
위처럼 클라이언트 관점에서 지연율 또한 크게 증가합니다.
게시글을 조회할 때, 발생하는 쿼리
게시글을 전체조회할 때, 발생하는 쿼리입니다. 예시 코드입니다.

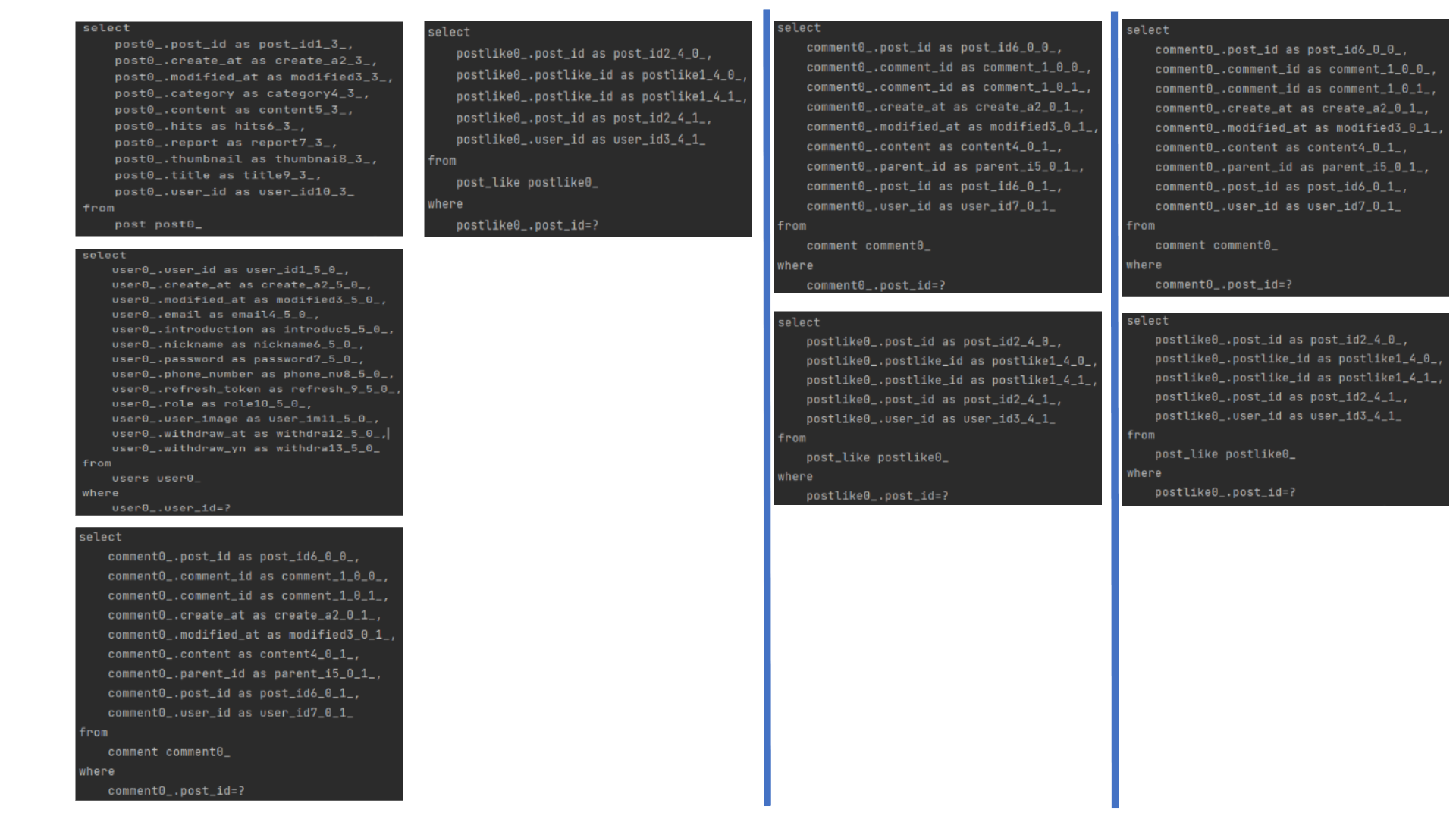
"N + 1 쿼리!"
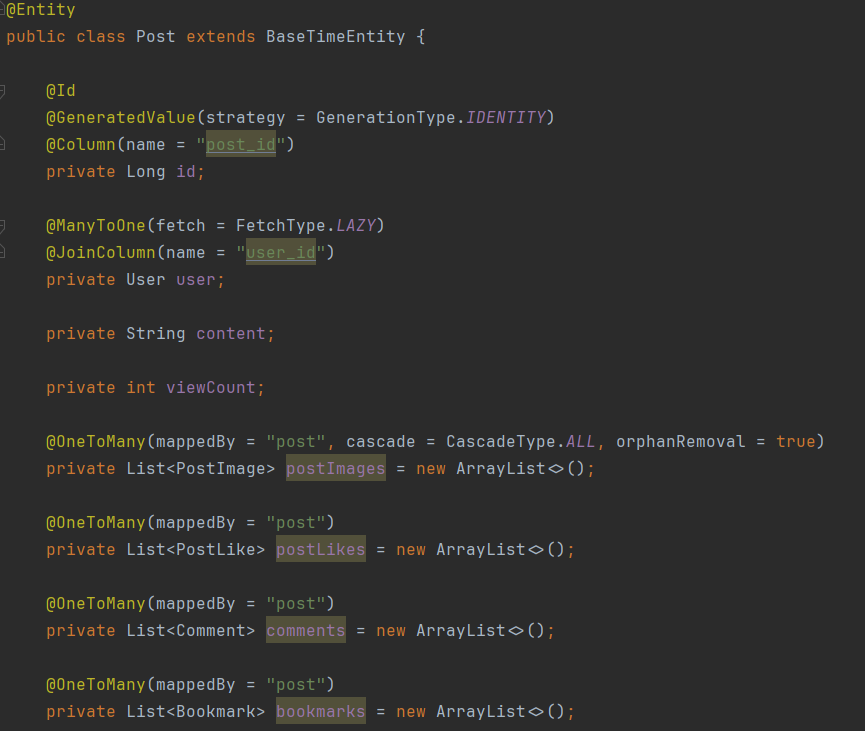
게시글 하나를 조회하고 USER, COMMENT, LIKE, ...등을 조회합니다.
총 4개의 테이블이 연관관계가 맺어져있고,
Lazy Loading으로 필요한 곳에서 사용되기 때문에N + 1 쿼리 문제가 발생합니다.
지금은 Post가 3개이기 때문에 첫 조회(1) + 1개의 user, 3개의 Comment, 3개의 like (7) = 8 밖에 발생하지 않았지만 ,
Post 조회 결과가 10만개, User 조회 결과 10만개, ...등등이 넘으면 어떻게 될까?단순하게 등록되어있는 게시글을 조회하는 로직에서 DB 조회가 이렇게 많이 발생하는 건 말이 안 됩니다.
2. N + 1 문제 해결방법
2.1 Eager Loading으로 N + 1 문제 해결과 문제점
Eager Loading은 연관된 Entity객체를 한번에 조회하도록 하는 기능입니다.
N + 1 문제를 해결해줄 수 있지만 사용하지 않는 것이 좋습니다.
Eager Loading을 사용하면 안 되는 이유
1. Entity 관계가 복잡해지면 N + 1 문제가 해결되지 않는 경우가 존재합니다.
2. 필요없는 데이터까지 불러오기 때문에 비효율적일 수 있습니다.
3. 예상할 수 없는 SQL이 발생합니다.
2.2 Fetch Join 적용과 문제점
현재 Fetch Join을 적용할 수 없는 이유
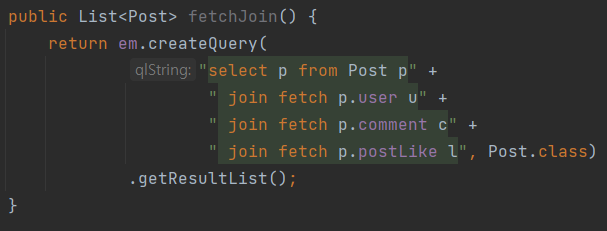

이렇게 1 : N 관계의 자식 테이블 여러곳에 Fetch Join을 사용하면 에러가 발생합니다.
이유는 다음과 같습니다.
Post를 조회할 때, POSTLIKE, COMMENT, BOOKMARK, POSTIMAGE 등 여러 OneToMany 관계가 존재합니다.
JPA에서 Fetch Join의 조건은 다음과 같습니다.
- ToOne은 몇개든 사용 가능하다.
- ToMany는 1개만 가능하다.
OneToMany 관계가 한 개 존재한다면, 쿼리 한방으로 해결할 수 있지만 위에 같은 상황에서는 불가능합니다.
자세한 내용
1. Fetch Join과 일반 Join의 차이
Fetch Join은
ORM에서 사용을 전제로 DB Schema를 Entity로 자동 변환해주고 영속성 컨텍스트에 영속화 해줍니다.
이러한 이유로 Fetch Join을 사용하면 연관 관계는 영속성 컨텍스트 1차 캐시에 저장되어 엔티티를 탐색하더라도 조회 쿼리가 발생하지 않습니다.
일반 Join은
단순히 데이터를 조회하는 개념으로 영속선 컨텍스트나 Entity와 무관합니다. 따라서 조회 쿼리가 발생합니다.
2. Collection Fetch Join은 하나만 가능합니다.
위와 같이 여러 Collection을 Fetch Join하게 되면 에러가 발생합니다.
3. Fetch Join을 Collection에 적용하였을 경우 중복이 발생합니다.
만약 Post와 Comment를 Fetch Join하였을 경우, 1:N 관계이기 때문에 1쪽의 데이터는 중복된 상태로 조회하게 됩니다.
| 레코드 | Post | Comment |
| 1 | Post1 | Comment1 |
| 2 | Post1 | Comment2 |
위와 같이 데이터 중복이 발생합니다.
3.1 Distinct 절을 사용하여 해결할 수 있습니다.
Distinct를 사용하면 해결할 수 있습니다.
JPQL Distinct와 SQL Distinct는 다릅니다.
SQL의 Distinct는 DB에서 수행되며 Post가 겹쳐도 Comment가 겹치지 않기 때문에 제거할 수 없습니다.
반면, JPQL의 Distinct는 Entity 객체에서 Distinct가 수행되기 때문에 중복되는 Post를 제거할 수 있습니다.
4. Paging을 할 수 없습니다.
ManyToOne, OneToOne 관계는 Fetch Join을 원하는만큼 사용할 수 있습니다.
이 경우 테이블을 조인해도 데이터 수에 변함이 없기 때문입니다.
그러나, OneToMany, ManyToMany 같은 Collection Fetch Join에서는 Paging이 불가능합니다.
일대다 테이블을 조인하면 데이터의 수가 변하기 때문입니다.
그럼 distinct를 사용하면 되지 않나요?
JPA에서 Paging을 하면서 Collection Fetch Join하는 것 자체를 동작하지 않게 막아두었습니다.
distinct를 적용하는 것은 불가능합니다.
Fetch Join을 적용하더라도 경고 로그를 남기면서 모든 데이터를 메모리에 불러와서 매우 위험합니다.(메모리 과부화)
따라서 Paging이 필요하다면 일반 Join쿼리를 사용하거나, BatchSize 옵션을 사용해야 합니다.
2.3 Hibernate default_batch_fetch_size 적용하기
현재 문제
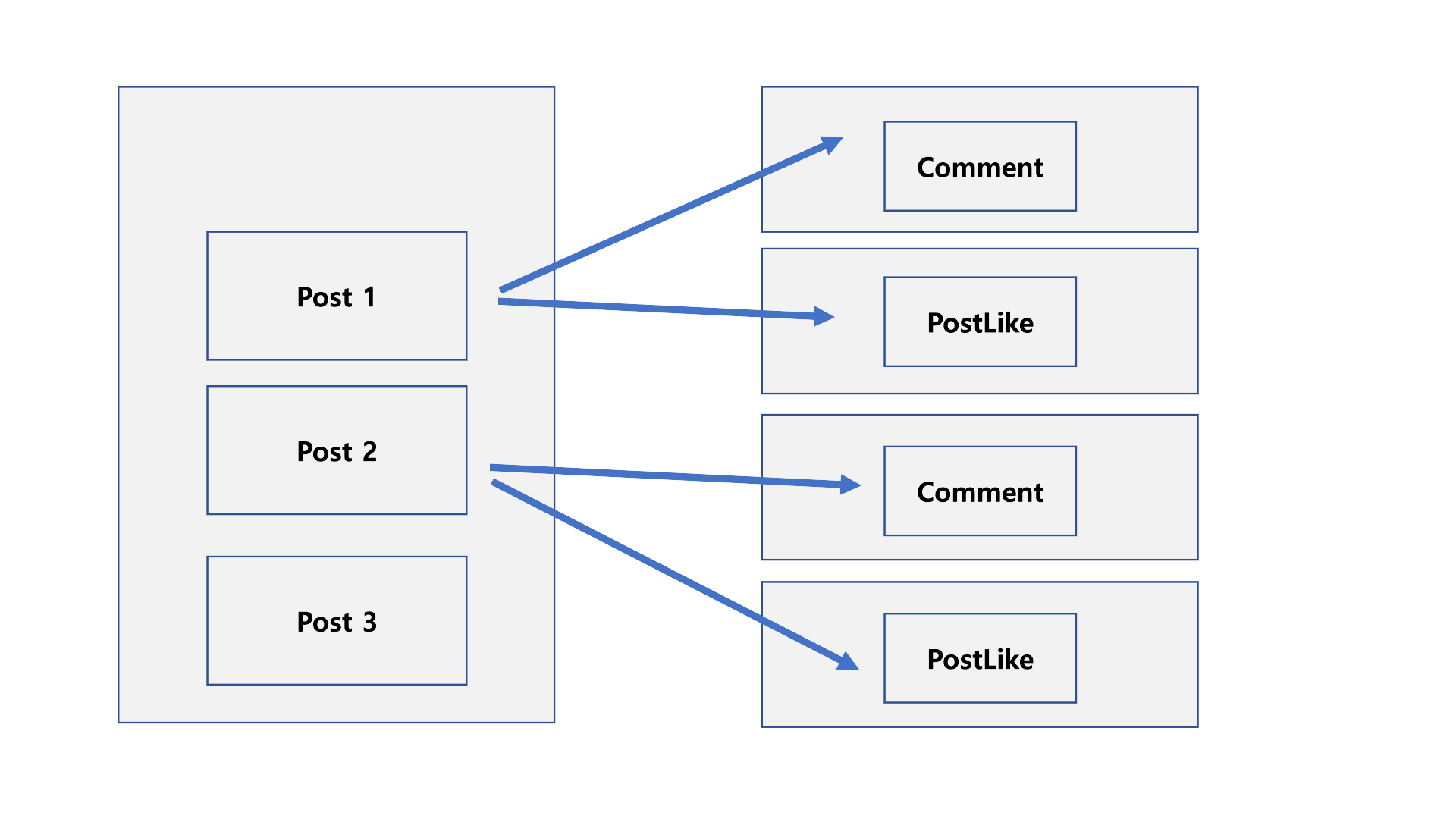
N + 1 문제를 그림으로 확인하겠습니다.
N + 1 문제는 결국 부모 엔티티와 연관 관계가 있는 자식 엔티티들의 조회 쿼리가 문제입니다.
Post1의 값에서 Comment, PostLike 조회를 하고,
Post2의 값에서 Comment, PostLike 조회를 하고 계속 .....
부모에서 자식의 값을 계속 조회하기 때문에 발생하는 문제라고 생각하면 됩니다.
in절로 묶어서 조회하면 해결할 수 있습니다.
hibernate.default_batch_fetch_size 옵션으로 해결할 수 있습니다.
Lazy Loading시 프록시 객체를 조회할 때, in절로 묶어서 한번에 조회할 수 있게 해주는 옵션입니다.
yml에 전역으로 적용 가능하며, @BatchSize를 통해 적용할 수 있습니다.
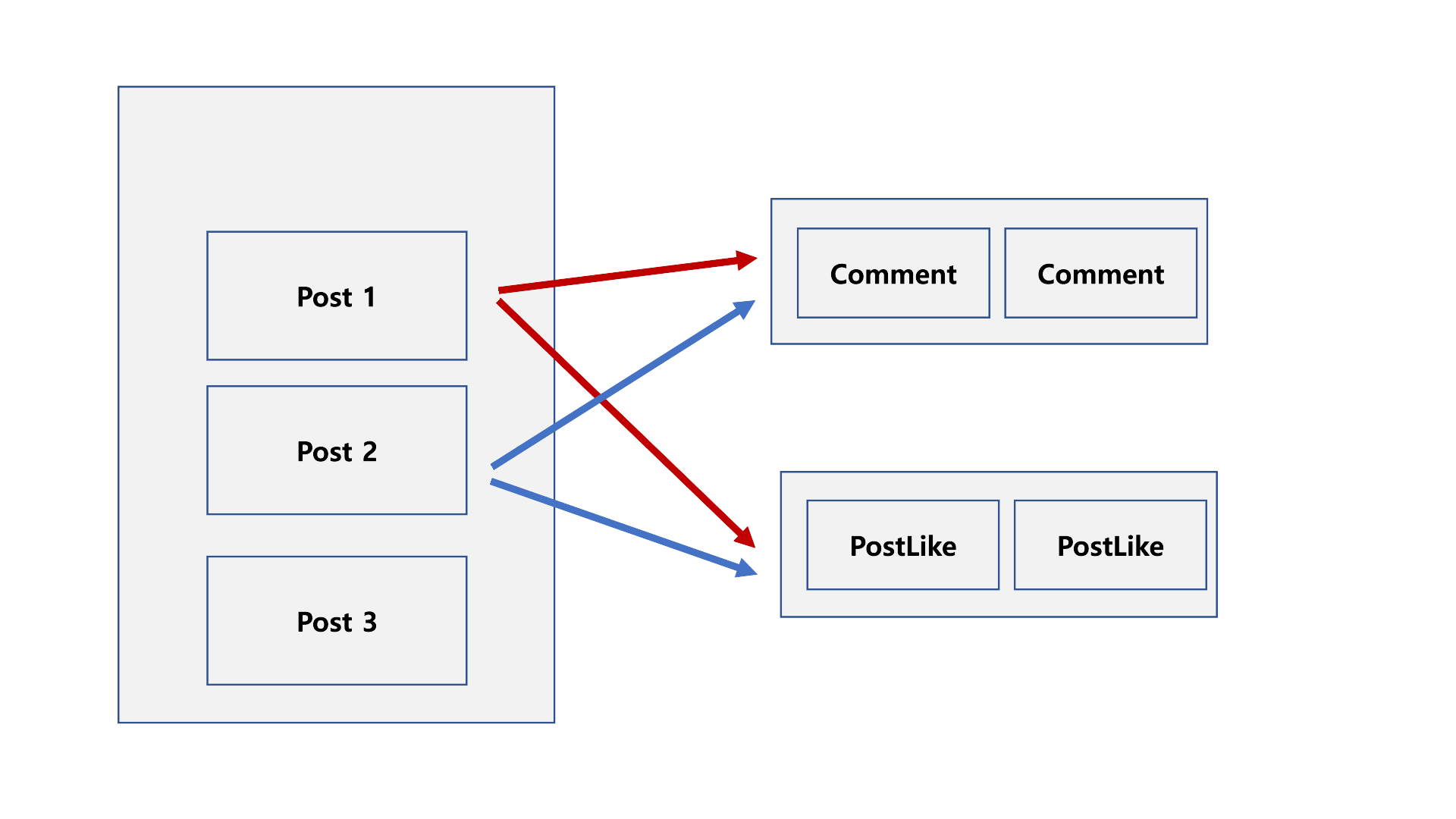
size를 1000으로 설정하면, 1000개 단위로 조회한다는 뜻입니다.
따라서 쿼리 수행수가 1 / 1000이 된다는 뜻입니다.
바로 코드로 확인해보겠습니다.
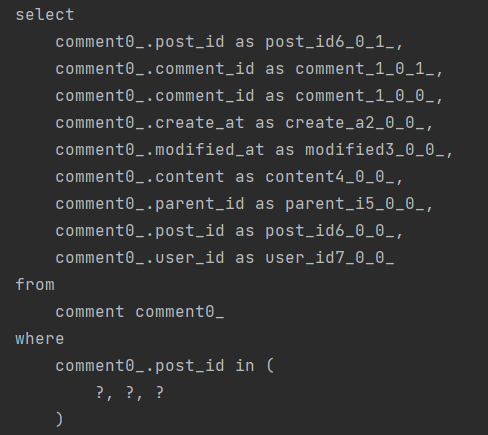
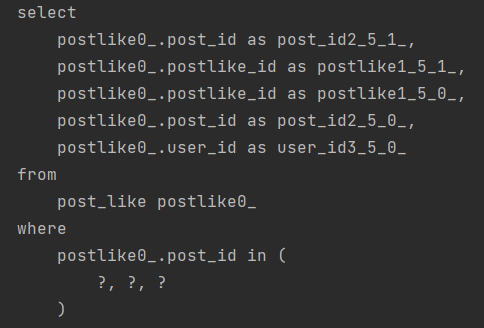
in (?, ?, .......)인 것을 확인할 수 있습니다.
6~7번 이상 반복되는 쿼리가 3번으로 개선
결과가 많으면 많을수록 엄청난 성능 개선입니다.
Tip)
보통 옵션값을 1,000 이상 주지 않는다.
1,000개 이상일 때 문제가 발생할 수 있음!
BatchSize를 적용한 후, 조회 속도 차이
위 N + 1이 문제가 되는 이유에서 성능 관점에서도 문제가 발생하며, 속도가 매우 느린 것을 확인할 수 있습니다.
그럼 BatchSize를 1000개를 적용한 후, 똑같이 게시글 10,000개를 조회하면 어떻게 될까요?
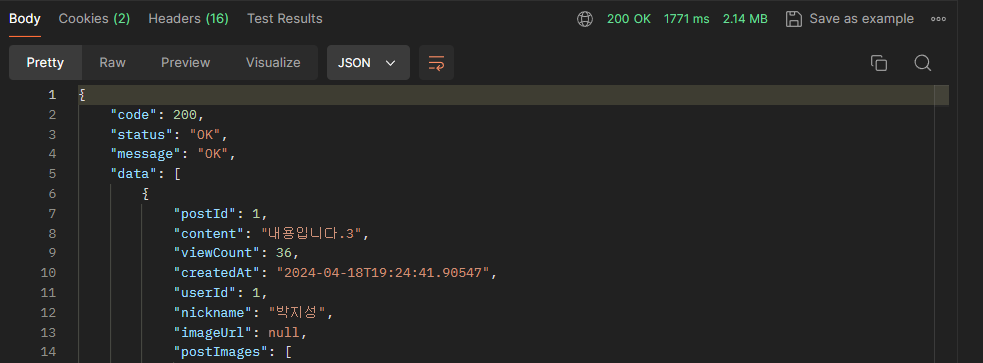
약 13초가 걸렸던 조회가 2초도 안 걸림을 알 수 있습니다.
설정 방법
application.yml
spring:
jpa:
properties:
hibernate.default_batch_fetch_size: 1000글로벌 설정을 통해서 모든 프로젝트에 적용됩니다.
2.4 Fetch Join 과 Batch Size 비교 분석
Fetch Join의 한계를 Batch Size로 해결
Collection Fetch Join을 사용하면 Paging문제나 한개만 Fetch Join할 수 있는 문제를 해결할 수 있습니다.
데이터 전송량 관점에서 Batch Size가 더 유리합니다.
Fetch Join은 Join을 하고 나서 가져오기 때문에 중복 데이터를 많이 가져와야 합니다.
Fetch Join
| 레코드 | Post | Comment |
| 1 | Post1 | Comment1 |
| 2 | Post1 | Comment2 |
| 3 | Post2 | Comment3 |
BatchSize
| 레코드 | Post |
| 1 | Post1 |
| 2 | Post2 |
| 레코드 | Comment |
| 1 | Comment1 |
| 2 | Comment2 |
| 3 | Comment3 |
2.5 일반 Join후 Projection을 사용하여 특정 컬럼만 Dto로 조회하는 방식
예시 코드
@Query("select new sutdy.datajpa.dto.MemberDto(m.id, m.username, t.name) " +
"from Member m join m.team t")
List<MemberDto> findMemberDto();장점
Entity 컬럼이 많을 때 특정 컬럼만 조회할 수 있습니다. 따라서 커버링 인덱스 활용 가능성 상승합니다.
단점
영속성 컨텍스트와 무관하게 동작하고 Dto에 의존하기 때문에 API 변경시 DAO도 수정해야 할 수 있습니다.
이러한 방식을 사용하려면 DAO를 분리하는 것이 좋습니다.
3. 결론
1. 1:1 연관관계나 ManyToOne은 최대한 Fetch Join을 사용하고, Collection 연관관계는 BatchSize를 활용합니다.
2. 특정 컬럼만 조회하거나 커버링 인덱스를 활용하고 싶은 경우 일반 Join후 Projection을 사용하여 Dto로 조회합니다.
'JPA' 카테고리의 다른 글
| JPA: 알람 기능과 댓글 기능, 도메인 로직과 서비스 로직의 트랜잭션 분리 작업 (0) | 2024.06.11 |
|---|---|
| JPA: 페이징이 필요한 이유와 페이징 성능 개선하기 - No Offset 사용 (0) | 2024.06.05 |
| JDBC, JPA) 싱글벙글 JPA 프로젝트에서 이미지 업로드 쿼리를 최소화 해보자 (0) | 2023.08.08 |
| Querydsl: OneToMany 관계에서 Projection DTO 값 List를 어떻게 갖고올까? (0) | 2023.04.01 |